
The Operations Intelligence Loop: How Professional Services Firms Stop Executing and Start Learning
Most firms automate tasks. The best ones automate the feedback loop. Here's the six-stage architecture that turns workflow automation into a self-improving operating system for underwriting, reporting, and data-intensive work.
Most firms automate tasks. The best ones automate the feedback loop. There is a significant difference between those two things — and it is the difference between a workflow tool and an actual operating system.
A workflow tool executes a process and stops. An operating system executes, measures, learns, and adjusts. The firms pulling ahead in underwriting, financial reporting, compliance, and client data workflows are not just automating faster — they are building systems that compound. Every cycle makes the next cycle more accurate, faster, and less dependent on human intervention.
We call this the Operations Intelligence Loop. Here is how it works.
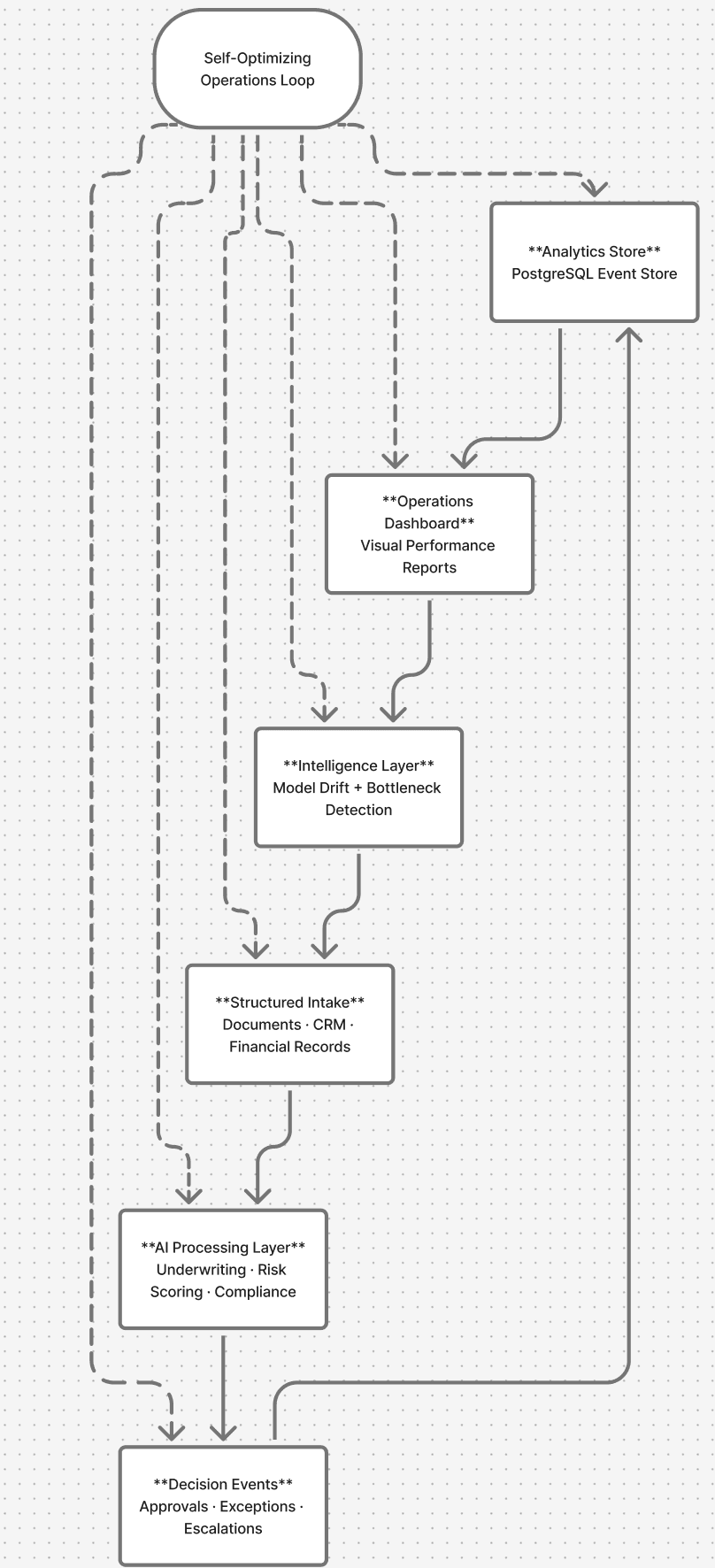
1. Structured Intake
An agent pulls from every source your team touches — loan files, financial statements, property records, CRM data — and structures raw inputs into clean, queryable information. No analyst prepping spreadsheets before the run. No copy-paste between systems. The intake layer handles document parsing, field extraction, and normalization automatically, so by the time data enters the workflow it is already in the shape the processing layer needs.
2. AI Processing Layer
That structured data hits the processing layer, where rules engines and AI models execute the logic your workflow requires — underwriting criteria, risk scoring, compliance checks, report generation. The work that used to take days runs in minutes. Critically, the processing layer is configurable: the same architecture that scores loan applications can generate client portfolio reports or run regulatory flag checks, depending on what the workflow demands.
3. Decision Events
Every output generates a structured event — an approval, an exception, an escalation. Nothing gets lost in an inbox or a Slack thread. Every decision is logged with its inputs, the logic applied, and the outcome. This is what makes the system auditable and what makes the feedback loop possible: you cannot improve what you cannot trace.
The firms building feedback loops now will be operating at a level their competitors cannot replicate by the time they realize what happened.
4. Analytics Store
Decision data flows into a dedicated PostgreSQL event store, separate from operational systems. Decision data should not live next to transaction logs — the two have different query patterns, different retention requirements, and different audiences. The analytics store is queryable, structured, and built for the reporting and intelligence layers that come next. It is the memory of the system.
5. Operations Dashboard
Performance surfaces visually: exception rates, turnaround time by file type, model confidence scores, bottlenecks by workflow step. The dashboard gives human operators a clear view of what the system is doing and where friction exists. But dashboards alone do not close the loop — a human still has to read them, interpret them, and decide what to change. That is the step most implementations stop at. It is not enough.
6. Intelligence Layer
The intelligence layer is where the system stops being a reporting tool and starts being an operating system. It synthesizes what the analytics store is showing — not just displaying it, but interpreting it — and feeds recommendations back into the workflow. It flags model drift before it becomes a problem. It identifies where exceptions cluster by document type, reviewer, or data source. It surfaces where human review is being overused relative to the model's actual accuracy. And it closes the loop back to the intake and processing layers, adjusting parameters, thresholds, and routing logic based on what it has learned.
The result: the system does not just process files. It figures out where the friction is, why, and adjusts — without waiting for a human to notice.
What This Means in Practice
- No manual data pulls. Intake agents handle sourcing and normalization on every run.
- No "let me check the model." The intelligence layer monitors drift and surfaces anomalies automatically.
- No review cycles to identify bottlenecks. The dashboard and intelligence layer identify them in real time.
- No separate analytics project. The event store is built into the architecture from day one.
This is the piece most firms skip when they automate. Execution is straightforward. Feedback is what makes it compound. A workflow that gets 5% more accurate every quarter does not just save time — it creates a structural advantage that is very difficult for a competitor to close once it has been running for a year.
Who This Is For
The Operations Intelligence Loop is designed for professional services firms with high-volume, data-intensive workflows: commercial lenders running underwriting at scale, accounting and advisory firms producing recurring client reports, compliance teams processing regulatory filings, and real estate operators managing large property portfolios. Anywhere the work is structured, repeatable, and data-dependent — the loop compounds.
BerTech designs and deploys these architectures. If your firm is running workflows that depend on manual data preparation, sequential approvals, or dashboards that require a human to interpret before anything changes — we would like to show you what the loop looks like in your environment.
Ready to get governance in place?
Take the free AI Governance Risk Score to understand your firm's current exposure, or talk to BerTech about building a governance program.